„Wie skaliert das System?“
„Ist hier bereits eine Effizienzplanung integriert?“
„Wie flexibel kann bei Bedarf hoch-/runterskaliert werden?“
Diese typischen Fragen kennt wohl jeder ITler zur Genüge. Und tatsächlich ist das Thema Skalierbarkeit als Hauptkriterium jeder IT-Infrastruktur auch seit Beginn ein wichtiger Bestandteil meiner Arbeit. Der Grund für die Signifikanz dieses Themas liegt auf der Hand: Die IT muss den immer weiter wachsenden Anforderungen der digitalen Welt gerecht werden und hierfür brauchen Unternehmen eine flexible und skalierbare Infrastruktur.
Skalierbarkeit beschreibt hierbei die Fähigkeit eines Systems, Netzwerks oder Prozesses zur Größenveränderung. Bei der Skalierbarkeit von IT-Infrastruktur kommt es vor allem darauf an, dass sich diese den ändernden Anforderungen einer Anwendung anpassen kann, indem Ressourcen hinzufügt oder entfernt werden. Dabei muss die Frage geklärt werden, welche Art von Skalierbarkeit benötigt wird, um die Nachfrage zu befriedigen. In den meisten Fällen wird dies durch Skalierung nach oben (Scale-Up) und/oder Skalierung nach außen (Scale-Out) erreicht.
Vertikale Skalierbarkeit – Scale-Up
Wir beginnen ganz am Anfang: Die Lösungen der SAP bewegen sich meist im monolithischen Umfeld, also in einer untrennbaren Einheit, zumindest zurzeit. Das bedeutet gleichzeitig, dass enorm große Datenbanken entstehen.
Wächst dieses System nun, muss auch die Hardware, die dieses System bereitstellt, mitwachsen. Dabei findet in der klassischen monolithischen Welt in der Regel eine Variante Anwendung: Die Scale-Up Variante.
Hierbei wird das System leistungsfähiger gemacht, indem die Hardware eines Rechners immer weiter aufgerüstet wird. Wir nehmen also denselben großen Datensatz und weisen diesem einfach immer mehr Hardware-Ressourcen zu, bis auch diese zur Neige geht.
Im klassischen Umfeld kann man dieses Beispiel auch einfach auf die Natur übertragen:
Stellen wir uns vor, unsere Datenbank ist ein Baum.
Dann ist der Server, auf dem diese operativ läuft, vergleichbar mit einem großen Blumentopf. Damit sind wir schon am ersten Problem angelangt: Der Blumentopf ist immer nur für eine „kurze“ Zeit passgenau. Zu Beginn muss unser Pflänzchen erst einmal in den Topf „hineinwachsen“ wohingegen es im späteren Verlauf schnell aus dem Topf „herauswächst“.
Genau dasselbe Problem hat man bei IT-Infrastrukturen – es ist zur Genüge durch Grafiken wie diese visualisiert:
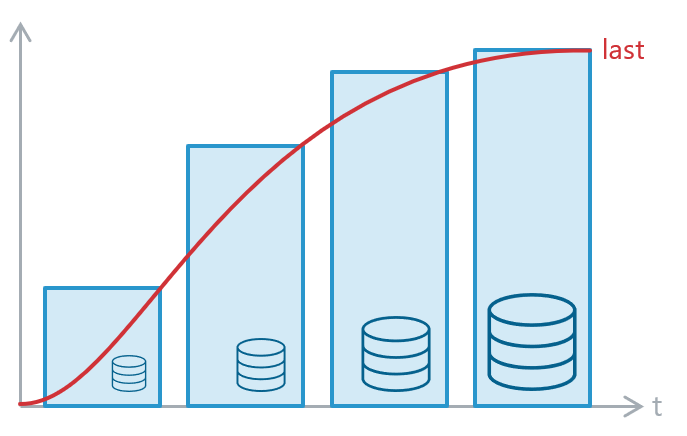
Quelle: Eigene Darstellung
Die Zeiten in denen unsere Datenbank „genutzt“ wird gibt es Phasen, in denen der metaphorische Baum sehr groß ist, in Zeiten der Nicht-Nutzung ist er hingegen sehr klein. Unser Baum schrumpft und wächst an einem Arbeitstag also mindestens je ein Mal. (vorausgesetzt alle arbeiten ungefähr in derselben Zeitzone)
Darüber hinaus wächst unsere Datenbank jeden Tag ein kleines bisschen weiter. Auf das Jahr betrachtet, stehen die blauen Kästen also für den nächst größeren Server, der immer auf die momentane Entwicklung geplant und vorauskalkuliert wird, so dass dieser auch perfekt passt.
Unser Blumentopf ist bei Anschaffung also nie voll ausgeschöpft und gegen Ende seiner Lebenszeit immer bis zum Maximum befüllt.
Diese Skalierungsmethodik nennt man Scale-Up, da im Grunde immer ein System in einen größeren Kasten gesteckt wird, um den Anforderungen gerecht zu werden.
Durch den Fortschritt in der IT und die höheren Geschwindigkeiten entstehen immer kleinere Zeitfenster, in denen die Systemhardware gewechselt werden muss, um die Leistungsbedürfnisse decken zu können.
Dieses Verfahren lässt sich natürlich auch auf den diversen SAP-zertifizierten Hyperscalern realisieren. Hier kann man immer von VM-Größe zu VM-Größe wechseln, wenn sich der Bedarf ändert. Dazu ist wichtig, welche VM-Größen von SAP zertifiziert wurden.
On Azure: Was ist SAP-zertifiziert?
Bei genauerem Betrachten wird schnell klar, dass hier nur sehr große Schritte möglich sind:
2tb 4tb 6tb 8tb 9tb 12tb 16 18 20 24 RAM
Und bei einem gewissen Punkt angelegt, ist aktuell hardwarebedingt keine „größere“ Maschine mehr möglich. Es gibt keinen Hersteller der mehr bietet, größer darf die Datenbank also bei Scale-Up-Systemen nie werden.
Die Methodik an sich ist darüber hinaus auch unpraktisch. Zur Veranschaulichung möchte ich einmal die Schritte im Groben durchgehen, die nötig sind, um ein solches System hoch zu skalieren:
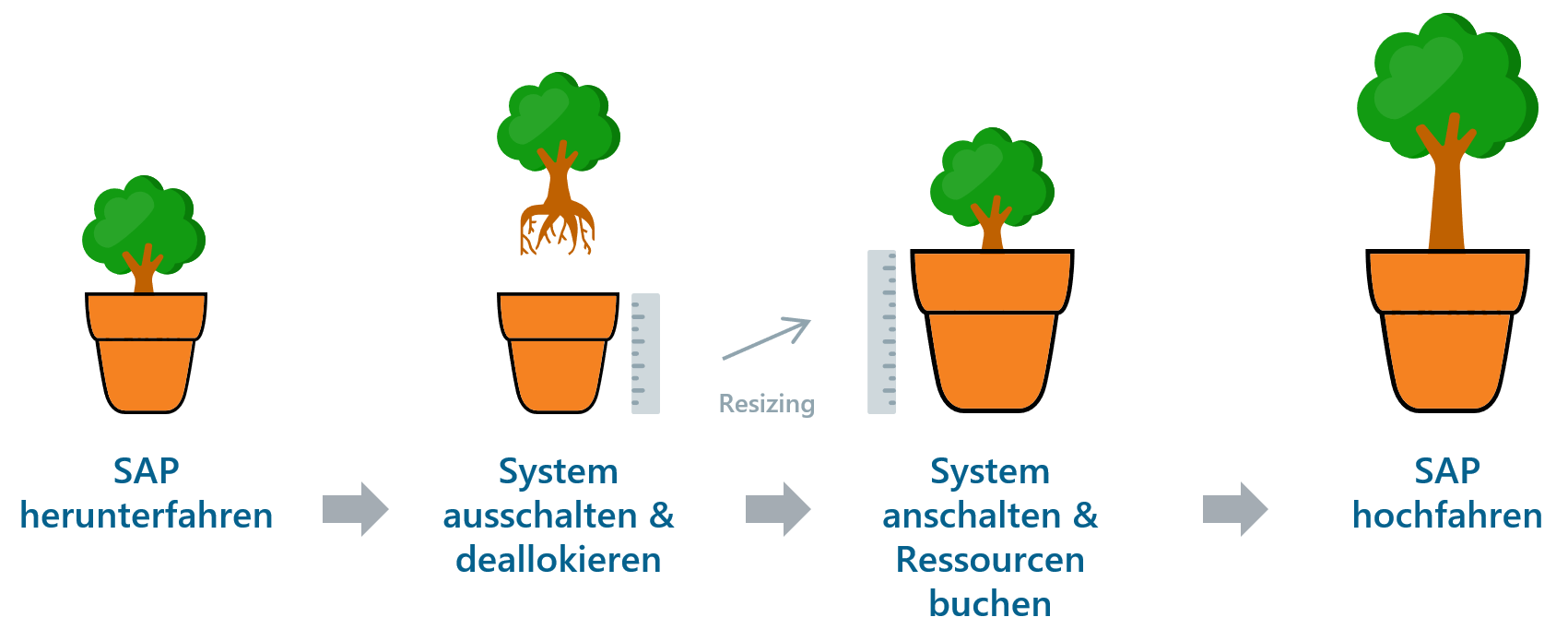
Quelle: Eigene Darstellung
Dies zeigt einen klassischen Infrastruktur Lebenszyklus. Es geht heutzutage aber auch effizienter:
Horizontale Skalierbarkeit – Scale-Out
Scale-Out mit einem Baum zu beschreiben, ist eher schwierig – und so kommt an dieser Stelle endlich der Titel ins Spiel.
Pilze oder Pilzkulturen werden in kleinen waagerechten „Regalen“ gepflanzt.
Benötigt man mehr Pilze, dann kann man bequem darunter oder darüber noch ein Regal hinzufügen, da die Pilze selbst nie besonders groß werden.
Übertragen auf unsere IT-Infrastruktur, haben wir in diesem Fall kein Baum, der immer weiter in die Höhe wächst, sondern legen für jeden Server, der dazu kommt, ein weiteres Pilzregal an. Der Zusammenschluss dieser Server stellt dann eine Datenbank dar, die beliebig erweitert werden kann.
Der Vorteil ist offensichtlich: Erhöht sich der Workload und mein System benötigt mehr Recheneinheiten, dann kann ich schlicht weitere Server hinzufügen und das System als Ganzes performanter machen.
Dadurch ergeben sich zwei bedeutende Vorteile:
- Das System bleibt bei der Erweiterung eingeschaltet
- Die Erweiterung kann in den notwendigen Schritten erfolgen
Darüber hinaus profitiert man von folgenden Möglichkeiten:
- eine Verkleinerung ist schnell umgesetzt
- die Verfügbarkeit kann mit Stand-By-Knoten so weit verbessert werden, dass Wartungsaufgaben keine Downtimes mehr benötigen. (z. B. OS-Patching)
- die Verfügbarkeit des Gesamtsystems steigt und man verliert den SPOF (Single Point of Failure) des „einen laufenden Servers“
SPOF: Single Point of Failure
Durch die horizontale Skalierung vermeidet man einen Single Point of Failure. Wenn also ein Bestandteil ausfällt, zieht dies nicht den Ausfall des gesamten Systems nach sich. So besteht die Möglichkeit, die Kapazitäten im laufenden Betrieb zu erhöhen.
Übertragen wir das Ganze einmal:
Wenn es möglich ist, dass meine Datenbank nie besonders „hoch“ wächst, kann ich mehrere „Kisten“ nebeneinander stellen.
Die Datenbank an sich, also der verbrauchte Speicher, kann jedoch weiterwachsen, nur eben die Teile, die operativ laufen, müssen getrennt und auf einzelne „Kisten“ verschoben werden.
Zum Glück bietet SAP solch eine Möglichkeit für diverse Datenbanken an:

Quelle: SAP
Stellt man mehrere „Worker“ bereit, die die aktiven Teile der Datenbank vorhalten, braucht man zwingend ein Speichermedium, welches von allen Systemen erreicht wird. NetApp bietet dazu fertige Storage Einheiten an, um die Datenbank zu speichern und performant an verschiedene Hosts anzubinden:

Quelle: Microsoft
Wir bekommen also eine fertige Pflanzbox für unsere Pilzkultur gestellt.
Fazit
Ich fasse also noch einmal zusammen: Während bei der Scale-Up Skalierung die vorhandene Hardware durch ständige Erweiterung des Basissystems immer größer wird, wird bei der Scale-Out Skalierung neue Hardware hinzugefügt und mit den bestehenden Komponenten verbunden.
Klar ist, beide Varianten haben ihre Daseinsberechtigung. Die Scale-Up Skalierung ist beispielsweise bis zu einem bestimmten Punkt einfach praktischer, gerade wenn es sich um kleine Datenbanken handelt. Wachsen die Daten jedoch schnell oder sollen sie in einem hochverfügbaren Szenario laufen, macht es Sinn sich früh mit der Scale-Out Technik und den verbundenen Möglichkeiten vertraut zu machen.
Nachdem ich nun die Grundlagen der Skalierbarkeit von IT-Infrastrukturen erläutert habe, gehe ich in meinem nächsten Blogbeitrag auf die Interaktion mit NetApp Storage, am Beispiel einer Azure Umgebung ein.